* Hint: Please click on the picture(s) in order to maximize it
* Hint:Please note that some of the screenshots and outputs in this post have been recreated in a lab
So this was an interesting case that landed on my desk from one of our very technical clients who basically use us solely for escalation. The client has a third party PBX integrated with Cisco Call-manager via multiple SIP trunks. One of the things that the client uses the PBX for is that when calls come into Cisco Call-manager, it is sent to the PBX where there are operators who answer calls and forward the calls on if need be. However, the client noticed that whenever the agents forwarded calls to his phone that is registered on call-manager, there was always an extra ‘0’ zero in the beginning of the Caller-ID of the calling-number. The client wanted to know where this extra zero was being added to the number. The client went on to say that there was always an extra zero on every call regardless of whether the call originated internally or externally.
My shift was coming to an end and there were so many gateways and trunks everywhere that I didn’t even know how the offending calls entered the network. As a result, I felt we would spend more time trying to rummage through Docs or configurations on call-manager as opposed to just grabbing a few traces and looking at it. With this thought in mind, I placed a test call from my mobile phone into the company and asked the operator to forward my call on to an internal user.
I collected traces from all the servers in the cluster and since I knew the time-of-call, called and calling number, it was easy to find my call in the traces. Here is what I found:
From the traces below we see a back-hauled signal to the Call-manager from Ip address 10.x0.xx.9.. This is the originating MGCP gateway where my call entered the network .
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
05/17/2013 15:27:34.337 CCM|MGCPBhHandler 10.x0.xx.9 – TCP msg available from Device|<CLID::StandAloneCluster><ct::4,100,135,1.808082><IP::10.X0.XX.9 ><LVL::Detailed>
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
After that, the gateway at 10.x0.xx.9 sends or backhauls the calling number and called number to call-manager
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
05/17/2013 15:27:34.337 CCM|In Message — PriEuroSetupMsg — Protocol= PriEuroProtocol|
05/17/2013 15:27:34.337 CCM|Ie – Ni2BearerCapabilityIe — IEData= 04 03 90 90 A3 |
05/17/2013 15:27:34.337 CCM|Ie – Q931ChannelIdIe — IEData= 18 03 A9 83 9B |
05/17/2013 15:27:34.338 CCM|Ie – Q931CallingPartyIe — IEData= 6C 0C 21 83 37 38 32 31 31 37 33 31 34 33 |<CLID::StandAloneCluster><
05/17/2013 15:27:34.338 CCM|Ie – Q931CalledPartyIe — IEData= 70 07 81 37 37 33 33 31 31 |<CLID::StandAloneCluster><
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
From the above we can see that the telephone number are written in ASIC format so 37 37 33 33 31 31 is basically equal to 773311 :
From the above I was able to confirm that this was my call because:
The calling number was 7821173143
The called number ended with 773311
The apparent incompleteness of the called-number is perfectly normal because the client subscribes to ‘direct Inward Dial ’ service.
From the below, we see that after the call was received from the gateway, the call-manager looked at the configured digit-manipulation on the gateway and applied it to the calling and called number. Hence we see that the incoming-calling-number was changed from 7821173143 to 07821173143.
In the second line we can see the call-manager announcing the newly ‘globalised’ (globalizeIncomingCgpn) in-coming-calling number as 07821173143
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
CCM|SPROCPri::globalizeIncomingCgpn – Adding prefix: 0, Digits to strip: 0, Cgpn Transformation CSS: |
05/17/2013 15:27:34.338 CCM|SPROC :: stripAndPrependDigits– The number 7821173143 is prepended with prefix 0, updated number=07821173143|
15:27:34.338 CCM|SPROCPri::globalizeIncomingCgpn – Globalized Cgpn = 07821173143
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
The snapshot below shows the digit manipulation that is configured on the gateway. Notice that nothing is applied to it? Then why did the trace show that the calling-number had been changed from 7821173143 to 07821173143. well did you notice that digit manipulation was set to default? Default means: ‘if there is no digit manipulation configurations on the gateway, apply the digit manipulation that is configurations on the device-pool and if there is nothing on the device-pool, check the Call-manger Service parameters ’.
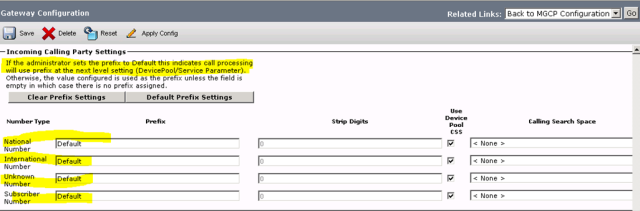
On this occasion, there was also no digit manipulation configured on the gateway so call-manager manipulated the digits based on service parameters. Based on the service parameter configuration below, we see that whenever a call that is classified as national comes into call-manager, a extra leading Zero (0) is added to the number.
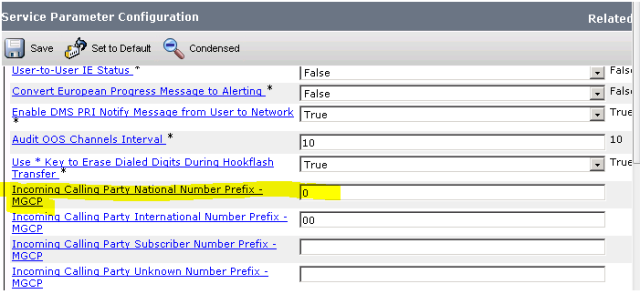
The next thing that the call-manger has to do is to find a route to the destination number of 773311 so it invokes digit analysis by triggering a digit analysis request (daReq).
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
05/17/2013 15:27:34.343 CCM|Digit Analysis: wait_DaReq: daReq.
CCM|Digit analysis: match(pi=”2″, fqcn=””, cn=”07821173143“, , dd=”773311“
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
From the trace below we find that the call-manager has found the a match for 773311
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
05/17/2013 15:27:34.343 CCM|Digit analysis: match(pi=”2″, fqcn=””, cn=”07821173143″,dd=”773311
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Now call-manager needs to process the call according to the match. In the trace below, we notice the following:
1) That the match is located at partition called ‘GW-INCOMING’
2) That called number was changed from 773311 to 3311.
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
05/17/2013 15:27:34.343 CCM|Digit analysis: analysis results|<CLID::StandAloneCluster><
05/17/2013 15:27:34.344 CCM||PretransformCallFingPartyNumber=07821173143
|CallingPartyNumber=07821173143
|DialingPartition=GW-INCOMING
|DialingPattern=3311
|FullyQualifiedCalledPartyNumber=3311
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
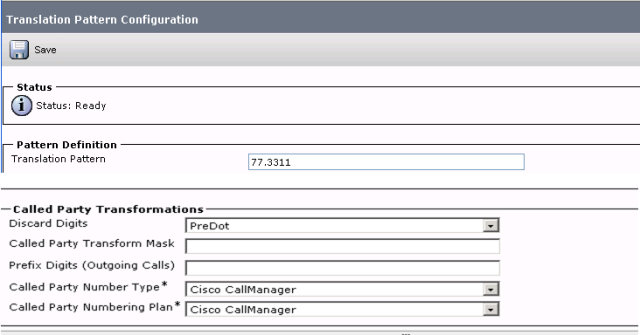
After noticing that the called-number had been changed, I jumped on call-manager to confirm what happened in the traces as it was now clear that a digit manipulation had just taken place because 773311 had just changed to 3311 . So I searched call-manager for the pattern that was just matched and I found a translation-pattern.
From the screenshot below, we can confirm that the dialed number matched the translation patter ‘77.3311’. We also see that the reason why the digit changed to 3311 was because the digit manipulated that was configured on the translation-pattern was configured to drop all the digits before 3311
Once again call manager tries to get the call to the intended destination by running the new called-number of 3311 through the digit analysis process and in the progress, call manager discovers that number has a Call-forward-all (cfa) value of 7165871 configured
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
callKey= 0x37D0D,
ssKey = 0, recordStatus 0,
dnPattern = 3311, dnPartition =
cfa = 7165871, cfaToVM = 0, cfaCss = PA
cfb = , cfbToVM = 0, cfbCss = PA
cfna = , cfnaToVM =
cfur = 7165871, cfurToVM
cfurInt = 7165871, cfurI
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
So based on the above, our Called or dialed number has just changed from 3311 to 7165871 because it had a (cfa) call-forward-all configured with a value of 7165871.
Therefore, call manager tried to forward the call by first of all carrying out a digit analysis in order to find a match or route.
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
5/17/2013 15:27:34.348 CCM|Forwarding – initiateCFA – CFA, callKey= 0x37D0D|
05/17/2013 15:27:34.350 CCM|Digit analysis: match(pi=”1″, fqcn=””, cn=”07821173143“,dd=”7165871”
As can be seen below, call-manager finds a match for the number it was looking for.
05/17/2013 15:27:34.350 CCM|Digit analysis: match(pi=”1″, fqcn=””, cn=”07821173143, dd=”7165871
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
Now let’s see what matches the call-manager found below.
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
|CallingPartyNumber=007821173143
|DialingPartition=SIP-Internal
|DialingPattern=716.XXXX
|FullyQualifiedCalledPartyNumber=7165871
|PotentialMatches=NoPotentialMatchesExist
|PretransformDigitString=7165871
|PretransformPositionalMatchList=716:5871
|CollectedDigits=5871
:::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::::
From the above, we can see that while call-manager was trying to find out how to get to ‘7165871’ by finding something that matched it, it found pattern ‘716.XXXX’ in partition ‘SIP-Internal ’.
Hello!? Did you notice that the calling number has changed from ‘07821173143’ to ‘007821173143’ ? if you didn’t take another look above
If you did then that is good. AS soon as I noticed this, I wanted to confirm what I had just seen in the logs above so I logged unto call manager web page and searched for 716.XXXX. The number was configured as a route-pattern but there was more to it: check out the screenshot of the configuration below
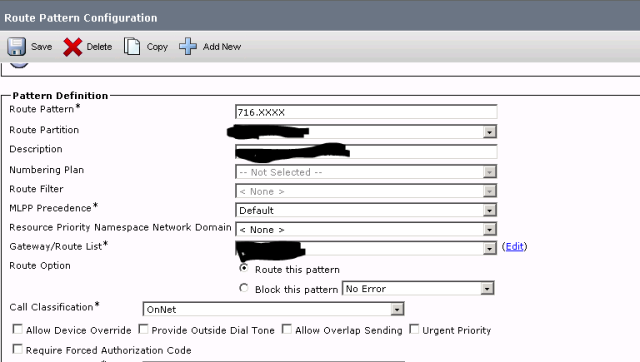
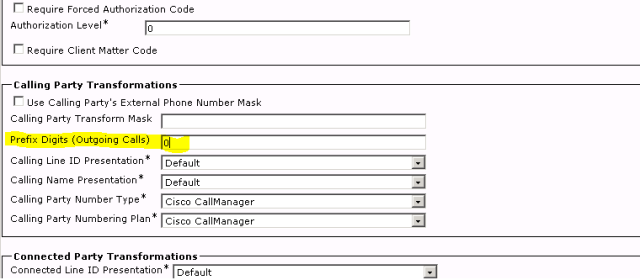
At this point my job was pretty much done. I confirmed that the route pattern was responsible for sending calls to the PBX by checking the route list. I also confirmed that this route pattern is the route-pattern that was responsible for sending the calls to the PBX with an extra zero. It was the root cause of the problem. So the cause of the problem was Cisco call manager and not the PBX. All I did was to remove the prefix of Zero and the problem was resolved. The client was very happy and straight away dropped another problem that needed solving on my lap. . . lol 🙂 from frying pan to fire 😉
Anyway, I hope you enjoyed this case as much as I did
Cheers




![IMG_0042[1]](https://voiceinitiate.files.wordpress.com/2014/01/img_00421.png)

![IMG_0045[1]](https://voiceinitiate.files.wordpress.com/2014/01/img_00451.png)
![IMG_0046[1]](https://voiceinitiate.files.wordpress.com/2014/01/img_00461.png)
![IMG_0048[1]](https://voiceinitiate.files.wordpress.com/2014/01/img_00481.png)
![IMG_0060[1]](https://voiceinitiate.files.wordpress.com/2014/01/img_00601.png)
![IMG_0061[1]](https://voiceinitiate.files.wordpress.com/2014/01/img_00611.png)
![IMG_0063[1]](https://voiceinitiate.files.wordpress.com/2014/01/img_00631.png)
![IMG_0050[1]](https://voiceinitiate.files.wordpress.com/2014/01/img_00501.png)
![IMG_0054[1]](https://voiceinitiate.files.wordpress.com/2014/01/img_00541.png)
![IMG_0059[1]](https://voiceinitiate.files.wordpress.com/2014/01/img_00591.png)

























